- AI, But Simple
- Posts
- Linear Attention For Transformers (Kimi Linear), Simply Explained
Linear Attention For Transformers (Kimi Linear), Simply Explained
AI, But Simple Issue #91
Edwin Dong & Lalit Julapalli
March 02, 2026

Hello from the AI, but simple team! If you enjoy our content (with 10+ custom visuals), consider supporting us so we can keep doing what we do.
Our newsletter is not sustainable to run at no cost, so we’re relying on different measures to cover operational expenses. Thanks again for reading!
Linear Attention For Transformers (Kimi Linear), Simply Explained
AI, But Simple Issue #91
We’re excited to share that we recently updated our website to a new, modern, and more visually pleasing look. It sports both dark and light modes; you can check it out at aibutsimple.com.
Quick Note: The login on this new page is completely separate from the beehiiv login. It is ONLY for courses. Everything is still hosted on the old website, which can be found by clicking any post on the new one.
We have added an exciting new addition: courses! 3 course options are now available, all of which are coming soon.
We’re also in the process of launching an upskilling/training program designed for businesses seeking to expand their AI expertise. If your organization is interested in learning more, please reach out to us at [email protected].
Today’s LLMs are built on the core principles of the attention mechanism, the key component of how LLMs generate and analyze text.
Attention has evolved over time as researchers and developers have found methods of optimizing its performance, which can be seen through the quality upgrades seen in transformer outputs.
This article will not be a formal literature review but rather a gateway into understanding the results and rationales behind evaluating new attention mechanisms and the inner workings of the Kimi Linear Attention mechanism, published in a 2025 paper by the Kimi team.
It will also be quite helpful to first find a familiarity with how transformer attention works.
We have recently published a two-part series of articles breaking down how modern transformers work, along with current advances that have improved the effectiveness of using attention.
A Review of Basic Transformer Attention
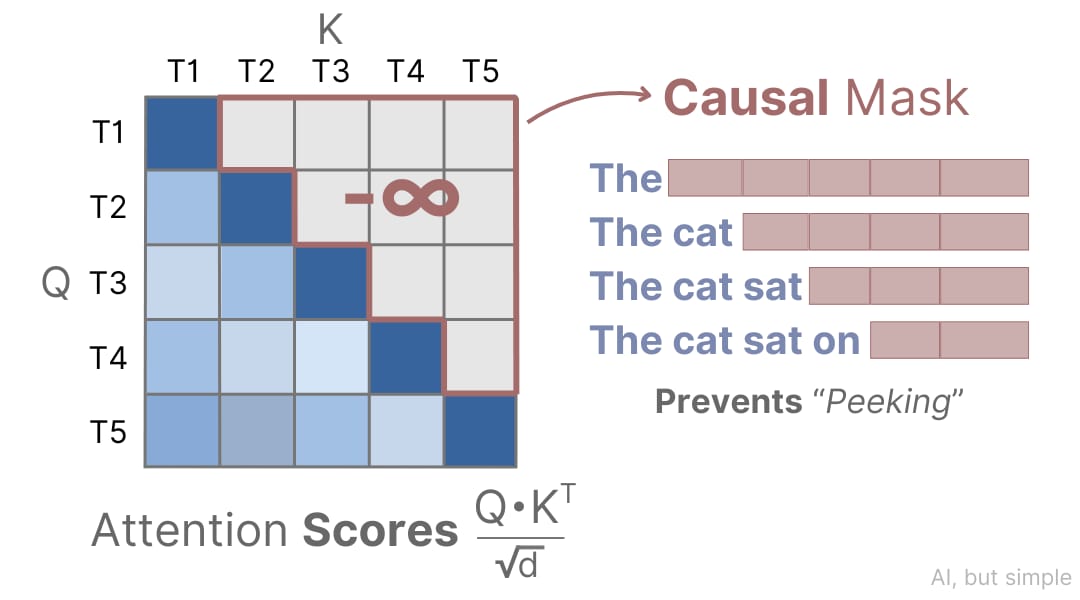
Breaking down attention to its very simplest component, we must understand that attention is calculated for each word/token by providing information about only words/tokens that came before it. This is what’s called the process of causal masking, illustrated below: