- AI, But Simple
- Posts
- Multimodal Large Language Models (MLLMs), Simply Explained
Multimodal Large Language Models (MLLMs), Simply Explained
AI, But Simple Issue #95
Edwin Dong & Anurag Shinde
March 30, 2026

Multimodal Large Language Models (MLLMs), Simply Explained
AI, But Simple Issue #95
Hello from the AI, but simple team! If you enjoy our content and custom visuals, consider sharing this newsletter with others or upgrading so we can keep doing what we do.
Most machine learning systems are built around a single modality. A language model reads text, an image classifier looks at pictures, and a speech recognizer processes audio.
Each is impressive within its functionality, but none resembles how humans actually perceive and reason about the world. We simultaneously read, see, hear, and combine modes effortlessly to understand what is happening around us.
Multimodal Large Language Models (MLLMs) are an attempt to close that gap. By connecting powerful language models to visual encoders and other modality-specific components, these models can receive an image, a video clip, or an audio recording alongside text and reason across all of them in a unified way.
MLLMs now power multimodal functionalities across major LLM providers, such as Gemini, Claude, and GPT. GPT-4V (Vision) led to a prominent breakthrough in MLLMs, and a large ecosystem of open and closed models has emerged rapidly around the same idea.
The Problem with Single-Modality Models
Large Language Models (LLMs) have shown remarkable emergent capabilities like instruction following, multi-step reasoning, and few-shot generalization.
However, they are inherently blind to everything that isn't text. They cannot look at a chart and describe what it shows. They cannot tell you whether the object in a photograph matches the description in the caption.
They process the world as a stream of tokens and nothing else.
Visual models have the opposite limitation. Systems like CLIP can represent images in a rich embedding space aligned with language, but they are not reasoning engines.
They can tell you that an image is semantically similar to a phrase, but they cannot write a story about it, answer a follow-up question about it, or explain why a meme is funny.
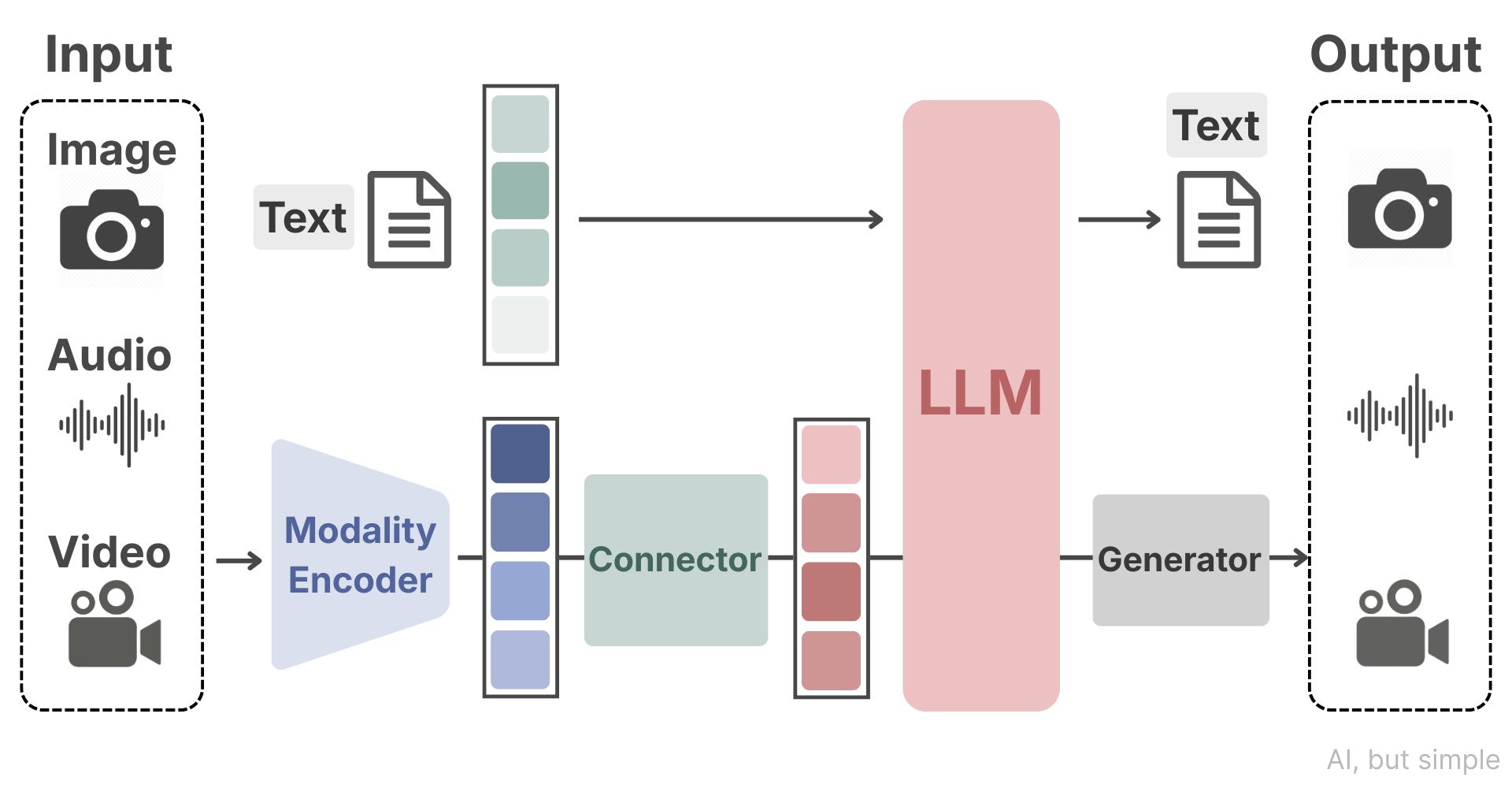
MLLMs resolve this by treating the LLM as the reasoning brain and the visual encoder as the sensory organ, with a learned connector bridging the two.
The Three-Part MLLM Architecture
A typical MLLM is built with three core modules that mimic how humans process information.
