- AI, But Simple
- Posts
- The Lottery Ticket Hypothesis, Simply Explained
The Lottery Ticket Hypothesis, Simply Explained
AI, But Simple Issue #92
Edwin Dong & Anurag Shinde
March 09, 2026

Hello from the AI, but simple team! If you enjoy our content (with 10+ custom visuals), consider supporting us so we can keep doing what we do.
Our newsletter is not sustainable to run at no cost, so we’re relying on different measures to cover operational expenses. Thanks again for reading!
The Lottery Ticket Hypothesis, Simply Explained
AI, But Simple Issue #92
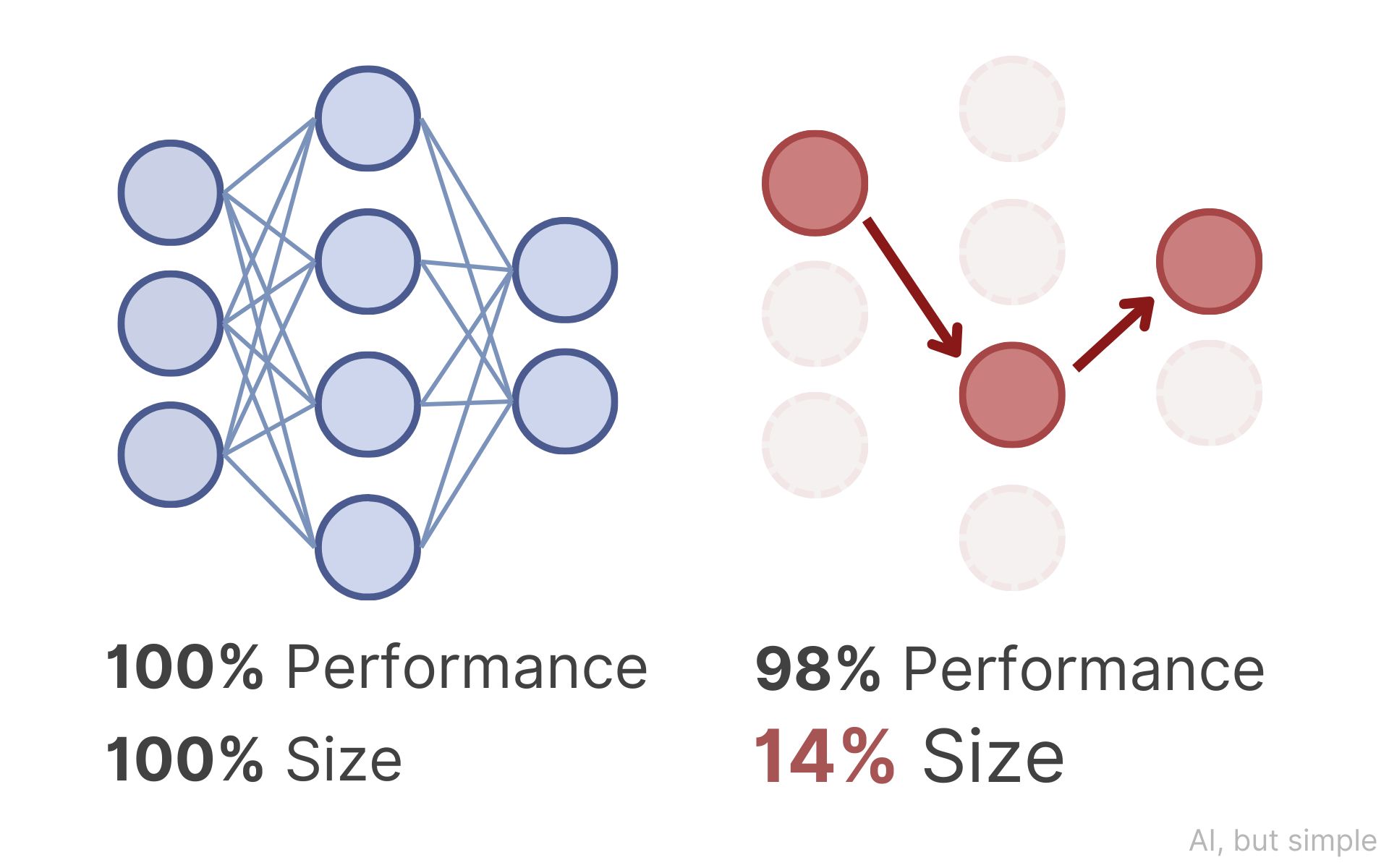
Deep neural networks are usually significantly over-parameterized. Modern models contain millions or billions of parameters, yet it has been routinely observed that large portions of them can be removed after training with little loss in performance.
But the natural follow-up question is deeper: Are these extra parameters just redundant, or were they necessary to discover the final solution?
In their landmark paper, “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks,” Jonathan Frankle and Michael Carbin propose a bold answer.